2014-06-19 20:04:42 +00:00
{
"metadata": {
"name": "",
2014-06-21 03:12:26 +00:00
"signature": "sha256:a96ed2f762cf56d93a4e5345428c7db5ec576916158ce54446dfdf837ec7e505"
2014-06-19 20:04:42 +00:00
},
"nbformat": 3,
"nbformat_minor": 0,
"worksheets": [
{
"cells": [
2014-06-19 21:57:31 +00:00
{
"cell_type": "markdown",
"metadata": {},
"source": [
"[Sebastian Raschka](http://sebastianraschka.com) \n",
"\n",
"- [Open in IPython nbviewer](http://nbviewer.ipython.org/github/rasbt/python_reference/blob/master/tutorials/multiprocessing_intro.ipynb?create=1) \n",
"\n",
"- [Link to this IPython notebook on Github](https://github.com/rasbt/python_reference/blob/master/tutorials/multiprocessing_intro.ipynb) \n",
"\n",
"- [Link to the GitHub Repository python_reference](https://github.com/rasbt/python_reference)\n"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"import time\n",
"print('Last updated: %s' %time.strftime('%d/%m/%Y'))"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
2014-06-20 15:09:14 +00:00
"Last updated: 20/06/2014\n"
2014-06-19 21:57:31 +00:00
]
}
],
2014-06-20 19:53:01 +00:00
"prompt_number": 1
2014-06-19 21:57:31 +00:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<hr>\n",
"I would be happy to hear your comments and suggestions. \n",
"Please feel free to drop me a note via\n",
"[twitter](https://twitter.com/rasbt), [email](mailto:bluewoodtree@gmail.com), or [google+](https://plus.google.com/+SebastianRaschka).\n",
"<hr>"
]
},
2014-06-19 20:04:42 +00:00
{
"cell_type": "heading",
"level": 1,
"metadata": {},
"source": [
"Parallel processing via the `multiprocessing` module"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
2014-06-20 15:09:14 +00:00
"CPUs with multiple cores have become the standard in the recent development of modern computer architectures and we can not only find them in supercomputer facilities but also in our desktop machines at home, and our laptops; even Apple's iPhone 5S got a 1.3 Ghz Dual-core processor in 2013.\n",
"\n",
"However, the default Python interpreter was designed with simplicity in mind and has a thread-safe mechanism, the so-called \"GIL\" (Global Interpreter Lock). In order to prevent conflicts between threads, it executes only one statement at a time (so-called serial processing, or single-threading).\n",
2014-06-19 20:04:42 +00:00
"\n",
2014-06-20 15:09:14 +00:00
"In this introduction to Python's `multiprocessing` module, we will see how we can spawn multiple subprocesses to avoid some of the GIL's disadvantages."
2014-06-19 20:04:42 +00:00
]
},
{
2014-06-20 15:09:14 +00:00
"cell_type": "markdown",
2014-06-19 20:04:42 +00:00
"metadata": {},
"source": [
2014-06-20 15:09:14 +00:00
"<br>\n",
"<br>"
2014-06-19 20:04:42 +00:00
]
},
{
2014-06-20 15:09:14 +00:00
"cell_type": "heading",
"level": 2,
2014-06-19 20:04:42 +00:00
"metadata": {},
"source": [
2014-06-20 15:09:14 +00:00
"Sections"
2014-06-19 20:04:42 +00:00
]
},
2014-06-19 21:57:31 +00:00
{
"cell_type": "markdown",
"metadata": {},
"source": [
2014-06-20 15:09:14 +00:00
"- [An introduction to parallel programming using Python's `multiprocessing` module](#An-introduction-to-parallel-programming-using-Python's-`multiprocessing`-module)\n",
" - [Multi-Threading vs. Multi-Processing](#Multi-Threading-vs.-Multi-Processing)\n",
"- [Introduction to the `multiprocessing` module](#Introduction-to-the-multiprocessing-module)\n",
" - [The `Process` class](#The-Process-class)\n",
" - [How to retrieve results in a particular order](#How-to-retrieve-results-in-a-particular-order)\n",
" - [The `Pool` class](#The-Pool-class)\n",
"- [Kernel density estimation as benchmarking function](#Kernel-density-estimation-as-benchmarking-function)\n",
" - [The Parzen-window method in a nutshell](#The-Parzen-window-method-in-a-nutshell)\n",
" - [Sample data and `timeit` benchmarks](#Sample-data-and-timeit-benchmarks)\n",
" - [Benchmarking functions](#Benchmarking-functions)\n",
" - [Preparing the plotting of the results](#Preparing-the-plotting-of-the-results)\n",
"- [Results](#Results)\n",
"- [Conclusion](#Conclusion)"
2014-06-19 21:57:31 +00:00
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<br>\n",
"<br>"
]
},
2014-06-19 20:04:42 +00:00
{
"cell_type": "heading",
2014-06-20 15:09:14 +00:00
"level": 3,
2014-06-19 20:04:42 +00:00
"metadata": {},
"source": [
2014-06-20 15:09:14 +00:00
"\n",
"Multi-Threading vs. Multi-Processing\n"
2014-06-19 20:04:42 +00:00
]
},
2014-06-19 21:57:31 +00:00
{
"cell_type": "markdown",
"metadata": {},
"source": [
2014-06-20 15:09:14 +00:00
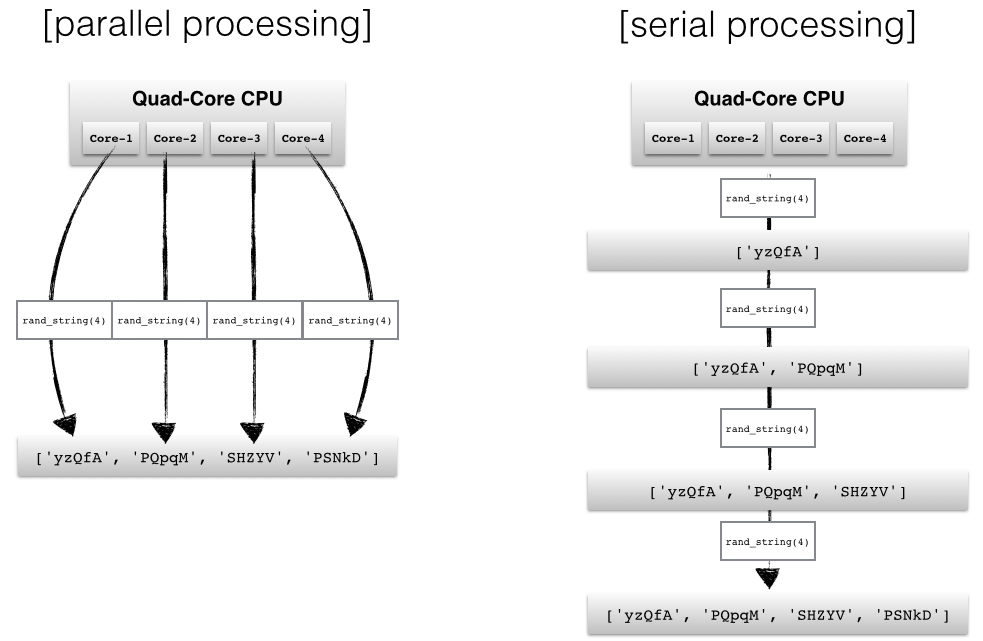
"Depending on the application, two common approaches in parallel programming are either to run code via threads or multiple processes, respectively. If we submit \"jobs\" to different threads, those jobs can be pictured as \"sub-tasks\" of a single process and those threads will usually have access to the same memory areas (i.e., shared memory). This approach can easily lead to conflicts in case of improper synchronization, for example, if processes are writing to the same memory location at the same time. \n",
2014-06-19 21:57:31 +00:00
"\n",
2014-06-20 15:09:14 +00:00
"A safer approach (although it comes with an additional overhead due to the communication overhead between separate processes) is to submit multiple processes to completely separate memory locations (i.e., distributed memory): Every process will run completely independent from each other.\n",
2014-06-19 21:57:31 +00:00
"\n",
2014-06-20 15:09:14 +00:00
"Here, we will take a look at Python's [`multiprocessing`](https://docs.python.org/dev/library/multiprocessing.html) module and how we can use it to submit multiple processes that can run independently from each other in order to make best use of our CPU cores."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
2014-06-19 21:57:31 +00:00
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<br>\n",
"<br>"
]
},
2014-06-19 20:04:42 +00:00
{
"cell_type": "heading",
2014-06-19 21:57:31 +00:00
"level": 1,
2014-06-19 20:04:42 +00:00
"metadata": {},
"source": [
"Introduction to the `multiprocessing` module"
]
},
2014-06-20 15:09:14 +00:00
{
"cell_type": "markdown",
"metadata": {},
"source": [
"[[back to top](#Sections)]"
]
},
2014-06-19 21:57:31 +00:00
{
"cell_type": "markdown",
"metadata": {},
"source": [
2014-06-19 22:26:19 +00:00
"The [multiprocessing](https://docs.python.org/dev/library/multiprocessing.html) module in Python's Standard Library has a lot of powerful features. If you want to read about all the nitty-gritty tips, tricks, and details, I would recommend to use the [official documentation](https://docs.python.org/dev/library/multiprocessing.html) as an entry point. \n",
2014-06-19 21:57:31 +00:00
"\n",
2014-06-19 22:26:19 +00:00
"In the following sections, I want to provide a brief overview of different approaches to show how the `multiprocessing` module can be used for parallel programming."
2014-06-19 21:57:31 +00:00
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<br>\n",
"<br>"
]
},
2014-06-19 20:04:42 +00:00
{
"cell_type": "heading",
"level": 3,
"metadata": {},
"source": [
"The `Process` class"
]
},
2014-06-20 15:09:14 +00:00
{
"cell_type": "markdown",
"metadata": {},
"source": [
"[[back to top](#Sections)]"
]
},
2014-06-19 20:04:42 +00:00
{
"cell_type": "markdown",
"metadata": {},
"source": [
2014-06-19 21:57:31 +00:00
"The most basic approach is probably to use the `Process` class from the `multiprocessing` module. \n",
2014-06-19 20:04:42 +00:00
"Here, we will use a simple queue function to compute the cubes for the 6 numbers 1, 2, 3, 4, 5, and 6 in 6 parallel processes."
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"import multiprocessing as mp\n",
2014-06-20 15:09:14 +00:00
"import random\n",
"import string\n",
"\n",
"random.seed(123)\n",
2014-06-19 20:04:42 +00:00
"\n",
"# Define an output queue\n",
"output = mp.Queue()\n",
"\n",
"# define a example function\n",
2014-06-20 15:09:14 +00:00
"def rand_string(length, output):\n",
" \"\"\" Generates a random string of numbers, lower- and uppercase chars. \"\"\"\n",
" rand_str = ''.join(random.choice(\n",
" string.ascii_lowercase \n",
" + string.ascii_uppercase \n",
" + string.digits)\n",
" for i in range(length))\n",
" output.put(rand_str)\n",
2014-06-19 20:04:42 +00:00
"\n",
"# Setup a list of processes that we want to run\n",
2014-06-20 15:09:14 +00:00
"processes = [mp.Process(target=rand_string, args=(5, output)) for x in range(4)]\n",
2014-06-19 20:04:42 +00:00
"\n",
"# Run processes\n",
"for p in processes:\n",
" p.start()\n",
"\n",
"# Exit the completed processes\n",
"for p in processes:\n",
" p.join()\n",
"\n",
"# Get process results from the output queue\n",
"results = [output.get() for p in processes]\n",
"\n",
"print(results)"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
2014-06-20 19:53:01 +00:00
"['BJWNs', 'GOK0H', '7CTRJ', 'THDF3']\n"
2014-06-19 20:04:42 +00:00
]
}
],
2014-06-20 19:53:01 +00:00
"prompt_number": 2
2014-06-19 21:57:31 +00:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<br>\n",
"<br>"
]
2014-06-19 20:04:42 +00:00
},
{
"cell_type": "heading",
"level": 3,
"metadata": {},
"source": [
2014-06-20 15:09:14 +00:00
"How to retrieve results in a particular order "
2014-06-19 20:04:42 +00:00
]
},
2014-06-19 21:57:31 +00:00
{
"cell_type": "markdown",
"metadata": {},
"source": [
"[[back to top](#Sections)]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
2014-06-20 15:09:14 +00:00
"The order of the obtained results does not necessarily have to match the order of the processes (in the `processes` list). Since we eventually use the `.get()` method to retrieve the results from the `Queue` sequentially, the order in which the processes finished determines the order of our results. \n",
"E.g., if the second process has finished just before the first process, the order of the strings in the `results` list could have also been\n",
"`['PQpqM', 'yzQfA', 'SHZYV', 'PSNkD']` instead of `['yzQfA', 'PQpqM', 'SHZYV', 'PSNkD']`\n",
"\n",
"If our application required us to retrieve results in a particular order, one possibility would be to refer to the processes' `._identity` attribute. In this case, we could also simply use the values from our `range` object as position argument. The modified code would be:"
2014-06-19 21:57:31 +00:00
]
},
2014-06-19 20:04:42 +00:00
{
"cell_type": "code",
"collapsed": false,
"input": [
"# Define an output queue\n",
"output = mp.Queue()\n",
"\n",
2014-06-20 15:09:14 +00:00
"# define a example function\n",
"def rand_string(length, pos, output):\n",
" \"\"\" Generates a random string of numbers, lower- and uppercase chars. \"\"\"\n",
" rand_str = ''.join(random.choice(\n",
" string.ascii_lowercase \n",
" + string.ascii_uppercase \n",
" + string.digits)\n",
" for i in range(length))\n",
" output.put((pos, rand_str))\n",
"\n",
2014-06-19 20:04:42 +00:00
"# Setup a list of processes that we want to run\n",
2014-06-20 15:09:14 +00:00
"processes = [mp.Process(target=rand_string, args=(5, x, output)) for x in range(4)]\n",
2014-06-19 20:04:42 +00:00
"\n",
"# Run processes\n",
"for p in processes:\n",
" p.start()\n",
"\n",
"# Exit the completed processes\n",
"for p in processes:\n",
" p.join()\n",
"\n",
"# Get process results from the output queue\n",
"results = [output.get() for p in processes]\n",
"\n",
"print(results)"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
2014-06-20 19:53:01 +00:00
"[(0, 'h5hoV'), (1, 'fvdmN'), (2, 'rxGX4'), (3, '8hDJj')]\n"
2014-06-19 20:04:42 +00:00
]
}
],
2014-06-20 19:53:01 +00:00
"prompt_number": 3
2014-06-20 15:09:14 +00:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And the retrieved results would be tuples, for example, `[(0, 'KAQo6'), (1, '5lUya'), (2, 'nj6Q0'), (3, 'QQvLr')]` \n",
"or `[(1, '5lUya'), (3, 'QQvLr'), (0, 'KAQo6'), (2, 'nj6Q0')]`\n",
"\n",
"To make sure that we retrieved the results in order, we could simply sort the results and optionally get rid of the position argument:"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"results.sort()\n",
"results = [r[1] for r in results]\n",
"print(results)"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
2014-06-20 19:53:01 +00:00
"['h5hoV', 'fvdmN', 'rxGX4', '8hDJj']\n"
2014-06-20 15:09:14 +00:00
]
}
],
2014-06-20 19:53:01 +00:00
"prompt_number": 4
2014-06-20 15:09:14 +00:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**A simpler way to to maintain an ordered list of results is to use the `Pool.apply` and `Pool.map` functions which we will discuss in the next section.**"
]
2014-06-19 21:57:31 +00:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<br>\n",
"<br>"
]
2014-06-19 20:04:42 +00:00
},
{
"cell_type": "heading",
"level": 3,
"metadata": {},
"source": [
"The `Pool` class"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
2014-06-19 21:57:31 +00:00
"[[back to top](#Sections)]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Another and more convenient approach for simple parallel processing tasks is provided by the `Pool` class. \n",
2014-06-19 20:04:42 +00:00
"\n",
"There are four methods that are particularly interesing:\n",
"\n",
" - Pool.apply\n",
" \n",
" - Pool.map\n",
" \n",
" - Pool.apply_async\n",
" \n",
" - Pool.map_async\n",
" \n",
"The `Pool.apply` and `Pool.map` methods are basically equivalents to Python's in-built [`apply`](https://docs.python.org/2/library/functions.html#apply) and [`map`](https://docs.python.org/2/library/functions.html#map) functions."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Before we come to the `async` variants of the `Pool` methods, let us take a look at a simple example using `Pool.apply` and `Pool.map`. Here, we will set the number of processes to 4, which means that the `Pool` class will only allow 4 processes running at the same time."
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"def cube(x):\n",
" return x**3"
],
"language": "python",
"metadata": {},
"outputs": [],
2014-06-20 15:09:14 +00:00
"prompt_number": 5
2014-06-19 20:04:42 +00:00
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"pool = mp.Pool(processes=4)\n",
"results = [pool.apply(cube, args=(x,)) for x in range(1,7)]\n",
"print(results)"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
"[1, 8, 27, 64, 125, 216]\n"
]
}
],
2014-06-19 21:57:31 +00:00
"prompt_number": 6
2014-06-19 20:04:42 +00:00
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"pool = mp.Pool(processes=4)\n",
"results = pool.map(cube, range(1,7))\n",
"print(results)"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
"[1, 8, 27, 64, 125, 216]\n"
]
}
],
2014-06-19 21:57:31 +00:00
"prompt_number": 7
2014-06-19 20:04:42 +00:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
2014-06-20 19:53:01 +00:00
"The `Pool.map` and `Pool.apply` will lock the main program until all a process is finished, which is quite useful if we want to obtain resuls in a particular order for certain applications. \n",
"In contrast, the `async` variants will submit all processes at once and retrieve the results as soon as they are finished. \n",
"One more difference is that we need to use the `get` method after the `apply_async()` call in order to obtain the `return` values of the finished processes."
2014-06-19 20:04:42 +00:00
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"pool = mp.Pool(processes=4)\n",
"results = [pool.apply_async(cube, args=(x,)) for x in range(1,7)]\n",
"output = [p.get() for p in results]\n",
"print(output)"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
"[1, 8, 27, 64, 125, 216]\n"
]
}
],
2014-06-19 21:57:31 +00:00
"prompt_number": 8
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<br>\n",
"<br>"
]
2014-06-19 20:04:42 +00:00
},
{
"cell_type": "heading",
2014-06-19 21:57:31 +00:00
"level": 1,
2014-06-19 20:04:42 +00:00
"metadata": {},
"source": [
2014-06-20 15:09:14 +00:00
"Kernel density estimation as benchmarking function"
2014-06-19 20:04:42 +00:00
]
},
2014-06-19 21:57:31 +00:00
{
"cell_type": "markdown",
"metadata": {},
"source": [
"[[back to top](#Sections)]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In the following approach, I want to do a simple comparison of a serial vs. multiprocessing approach where I will use a slightly more complex function than the `cube` example, which he have been using above. \n",
"\n",
"Here, I define a function for performing a Kernel density estimation for probability density functions using the Parzen-window technique. \n",
"I don't want to go into much detail about the theory of this technique, since we are mostly interested to see how `multiprocessing` can be used for performance improvements, but you are welcome to read my more detailed article about the [Parzen-window method here](http://sebastianraschka.com/Articles/2014_parzen_density_est.html). "
]
},
2014-06-19 20:04:42 +00:00
{
"cell_type": "code",
"collapsed": false,
"input": [
"import numpy as np\n",
"\n",
"def parzen_estimation(x_samples, point_x, h):\n",
2014-06-19 21:57:31 +00:00
" \"\"\"\n",
" Implementation of a hypercube kernel for Parzen-window estimation.\n",
"\n",
" Keyword arguments:\n",
" x_sample:training sample, 'd x 1'-dimensional numpy array\n",
" x: point x for density estimation, 'd x 1'-dimensional numpy array\n",
" h: window width\n",
" \n",
" Returns the predicted pdf as float.\n",
"\n",
" \"\"\"\n",
2014-06-19 20:04:42 +00:00
" k_n = 0\n",
" for row in x_samples:\n",
" x_i = (point_x - row[:,np.newaxis]) / (h)\n",
" for row in x_i:\n",
" if np.abs(row) > (1/2):\n",
" break\n",
" else: # \"completion-else\"*\n",
" k_n += 1\n",
" return (k_n / len(x_samples)) / (h**point_x.shape[1])"
],
"language": "python",
"metadata": {},
"outputs": [],
2014-06-19 21:57:31 +00:00
"prompt_number": 9
2014-06-19 20:04:42 +00:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<hr>\n",
"**A quick note about the \"completion else**\n",
"\n",
"Sometimes I receive comments about whether I used this for-else combination intentionally or if it happened by mistake. That is a legitimate question, since this \"completion-else\" is rarely used (that's what I call it, I am not aware if there is an \"official\" name for this, if so, please let me know). \n",
"I have a more detailed explanation [here](http://sebastianraschka.com/Articles/2014_deep_python.html#else_clauses) in one of my blog-posts, but in a nutshell: In contrast to a conditional else (in combination with if-statements), the \"completion else\" is only executed if the preceding code block (here the `for`-loop) has finished.\n",
"<hr>"
]
},
2014-06-19 21:57:31 +00:00
{
"cell_type": "heading",
"level": 3,
"metadata": {},
"source": [
"The Parzen-window method in a nutshell"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"[[back to top](#Sections)]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"So what this function does in a nutshell: It counts points in a defined region (the so-called window), and divides the number of those points inside by the number of total points to estimate the probability of a single point being in a certain region.\n",
"\n",
"Below is a simple example where our window is represented by a hypercube centered at the origin, and we want to get an estimate of the probability for a point being in the center of the plot based on the hypercube."
]
},
2014-06-19 20:04:42 +00:00
{
"cell_type": "code",
"collapsed": false,
"input": [
"%matplotlib inline"
],
"language": "python",
"metadata": {},
"outputs": [],
2014-06-19 21:57:31 +00:00
"prompt_number": 10
2014-06-19 20:04:42 +00:00
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"from mpl_toolkits.mplot3d import Axes3D\n",
"import matplotlib.pyplot as plt\n",
"import numpy as np\n",
"from itertools import product, combinations\n",
"fig = plt.figure(figsize=(7,7))\n",
"ax = fig.gca(projection='3d')\n",
"ax.set_aspect(\"equal\")\n",
"\n",
"# Plot Points\n",
"\n",
"# samples within the cube\n",
"X_inside = np.array([[0,0,0],[0.2,0.2,0.2],[0.1, -0.1, -0.3]])\n",
"\n",
"X_outside = np.array([[-1.2,0.3,-0.3],[0.8,-0.82,-0.9],[1, 0.6, -0.7],\n",
" [0.8,0.7,0.2],[0.7,-0.8,-0.45],[-0.3, 0.6, 0.9],\n",
" [0.7,-0.6,-0.8]])\n",
"\n",
"for row in X_inside:\n",
" ax.scatter(row[0], row[1], row[2], color=\"r\", s=50, marker='^')\n",
"\n",
"for row in X_outside: \n",
" ax.scatter(row[0], row[1], row[2], color=\"k\", s=50)\n",
"\n",
"# Plot Cube\n",
"h = [-0.5, 0.5]\n",
"for s, e in combinations(np.array(list(product(h,h,h))), 2):\n",
" if np.sum(np.abs(s-e)) == h[1]-h[0]:\n",
" ax.plot3D(*zip(s,e), color=\"g\")\n",
" \n",
"ax.set_xlim(-1.5, 1.5)\n",
"ax.set_ylim(-1.5, 1.5)\n",
"ax.set_zlim(-1.5, 1.5)\n",
"\n",
2014-06-20 15:09:14 +00:00
"plt.show()"
2014-06-19 20:04:42 +00:00
],
"language": "python",
"metadata": {},
"outputs": [
{
"metadata": {},
"output_type": "display_data",
2014-06-19 21:57:31 +00:00
"png": "iVBORw0KGgoAAAANSUhEUgAAAZQAAAGUCAYAAAASxdSgAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJzsnXeUVOX9/9/3Tp/ZQpG6LCxNQUXEgCJIEVgWUIkRCwqK\nDdFEjTExNiwYG/zUX+QY2/fYYn5BiFEhAZYOFiKgIUG/iqgUkaZI2d2pt/3+WJ/rnbv3ztyZuW1m\nn9c5niO7s3eeO+V5P5/OSJIkgUKhUCiUAmGdXgCFQqFQSgMqKBQKhUIxBSooFAqFQjEFKigUCoVC\nMQUqKBQKhUIxBSooFAqFQjEFKigUCoVCMQUqKBQKhUIxBSooFAqFQjEFKigUCoVCMQUqKBQKhUIx\nBSooFAqFQjEFKigUCoVCMQUqKBQKhUIxBSooFAqFQjEFKigUCoVCMQUqKBQKhUIxBSooFAqFQjEF\nKigUCoVCMQUqKBQKhUIxBSooFAqFQjEFKigUCoVCMQUqKBQKhUIxBSooFAqFQjEFKigUCoVCMQUq\nKBQKhUIxBSooFAqFQjEFKigUCoVCMQUqKBQKhUIxBSooFAqFQjEFr9MLoFD0kCQJqVQKPM/D7/fD\n4/GAYRgwDOP00igUigaMJEmS04ugUNSIogiO4+T/iIiIoohAICALDMtSI5tCcQvUQqG4CkmSIAgC\nGhoa4Pf7wbKs/J8kSYjH42AYBhzHAQBYloXX64XP56MCQ6E4DBUUimuQJAkcx0EQBNnNpYRYKcT1\nRYzrVCqFVCoFgAoMheIkVFAorkAURaRSKUiSJMdJRFFEPB6HIAjwer3weDxpf6MUGKBZkEjchQoM\nhWI/NIZCcRTi4iJxEiISx44dgyRJspVCHicIAliWhcfjkf/TC9ITgVF+xFmWhc/nkwWKCgyFYh5U\nUCiOQawJURRlMSFxkkQigVAoBL/fD47j5I2/qakJgUCACgyF4kKoy4viCFouLkEQ0NTUlCYQahiG\nSdv4lcJCxElPYNQpx0RckskkkskkACowFEohUEGh2IokSeB5HjzPg2EYecNOpVKIRqMIBoMIBoNo\namoydD2GYeD1euH1euXrmykwHo9Hjr94vV5aA0OhZIAKCsU2SG2J2sUVi8XAcRzKy8tlYSDkuoEb\nFRilBZJJYERRRGNjIwDIwqK0YKjAUCg/QQWFYjnKwDvw08bN8zyi0Sg8Hg8qKyst2ZwzCUwymYQo\nimnWi5bAkP9YloUoikgkEvL1qcBQKD9BBYViKWoXF7FKEokE4vE4wuEw/H6/bRtxPgKj/FstC4YK\nDIXSDBUUimXo1ZZEo1GIooiKigrNwDvBjgREIwJDrBOSUZbNRUYFhtJaoYJCMR11bQk55XMch2g0\nCp/Ph7Kysoyba6bfWSk0WgKTSCTkYL0RF5lynVRgKK0JKigUU9GrLUkkEkgkEohEIi1aquSC3Rsw\nEUSGYeD3+yGKIkRRBM/z4DgOkiTlLDCkHxlABYZSWlBBoZgGyYiSJAnBYFB2cZEU4MrKyqKv6yCN\nKokFI4qi7CIzKjDKGhoqMJRSggoKpWCUgXdRFAE0b57q2pJS3ByJwPh8PgAtBYY8RikQRgVGEAT4\nfD74/X4qMJSigAoKpSC0XFyiKCIWiyGVSqGsrEzebPO5drGRSWBIw0p1kaWewKRSKVlYyGNIfIcK\nDMWNUEGh5A2JIwBIE5NUKgWv14uKioq8XVylslEWIjDAT0kCQMtkBwBpnZSpwFCchgoKJWe0aksA\nyC1LvF5v1iyu1opSYEirFz2BUVtoWi4yMjuGQATG6/WmxW8oFDuggkLJCb32KdFoFDzPIxgMynUn\nZlGqm6JSILQERhRFJJNJ8DxvuNCSCIwkSXIPMyowFLuggkIxhLp9CtnYeJ5HU1MTvF4vKisrkUwm\nIQiCk0stWtQCE4vF5IaUPM8jmUzK3ZZzFRjye2UMhgoMxWyooFCyohzNq7RKksmk3D4lEAjYup7W\nABEX4sYiWWBEJPIRGHXciwoMxUyooFAykmv7FCI2haJ3nda84SnFA0BGgdHKAqMCQ7EaKigUTfTm\nlpD2KX6/nwbeLSabMGcSGI7jkEgkMk6z1BOYeDwOAHLshQoMxShUUCgtyDSaN5lMFtw+JZ/1tNaN\nLJf7NktgyPvNMAw4jmthwZA0ZSowFDVUUChpaNWWCIKAaDQKIHv7FLNcXsrr0U0rP8wQGKU7k8TS\nqMBQ9KCCQgGgX1vSGtqnGKEUEgGMCgx5rNoyNCIwyj5kVGBaH1RQKHIDR5JRRDaTTKN5rcZsS4fS\nEj2BIW36o9FozhZMKpWSkwOUAkM+V1RgShsqKK0YZW1JKpWSJycKgoCmpiZ4PJ6C2qdQigulwBAx\nUFbxi6KYt8AAkOtrqMCULlRQWimZaktisRhCoRACgUDOX/hStCxK8Z6MoEwjBtKnWRYqMEoLhsRg\nqMAUP1RQWiFatSUA5JOkEy6uTLTmLC83YURg9GbBkL9XuteA5hgd6WGmbhVDBab4cM+uQbEcvdoS\nnuflDsHl5eWu+xKrN6XWaC24kUwCY2RcMoAWAkPa+JDHq7PIKO6GCkorIdtoXq/XK8dQCsHMSnky\nrItSHJghMADSxENtwVCBcTdUUFoByvG06vYpkiShoqICyWTSlSd/0t2YbiD2QToVF0o+AqP8W6Cl\nBUMFxt1QQSlhMrVPaWpqQiAQQCgUcp2LiyAIAhoaGsCyrFzrQKBB3OIjk8AkEglZNEh35GwuMmJ1\nKwVGXQdDsRcqKCWK3twS0j6lkNG8VkM2Cp7nUV5eLt+DKIpIJBLy3HUAuidcivtRCkwgEJBHRxNX\nrCRJGV1k6j5kJEtRK02Zfj7sgQpKiaGeW6Jsn0KKF7Xap1jdJdgopM2LKIrw+/3wer1pJ1CSCeT1\netMsMJKKSjYPOg63+CCC4ff7wbJs2rhk4rKlAuNuqKCUEFq1JUDxtE9RrpNhmLTRtmrI/ZEmlbn2\nqSoGWnu6tHJcMoAWAgOgxfubi8CQFGVq4ZoHFZQSQau2JNf2KU4F5bVcceRLbxS9NiIkJZoU4dE+\nU9lxMjkjk4hmEhhixeYiMMSFSlAWWpI6GEpuUEEpcjLVlkSjUXg8HlRWVmb9cjj15SF9xIDsnYxz\nQUtgjKawUopjkJlSYIgFUojAJBIJcBwnH7yURZbFaOE6ARWUIkavtkQ5mteM2pJcyCWGko8rLt8Y\njZEMI7Lx0Crt4oO8X7kIjF6assfj0bRgqMBkhwpKkSIIAmKxmOwmUtaWaI3mzYadFehuyDbTyjAi\nm486g8yN9TmliBVzdHIRGK2/V66NCkx2qKAUGUoXF/k3wzDyaF6fz+fq0by5uLjs3MgzuU+Ur7XS\ngqFYgxWvrZbAkEMEyRIkkPdZbcFQgckOFZQiIlNtSSKRsH00rxaZLB1SUGnExeXkl1G9+ZAuAizL\nyptPsWeQtXa0YmyxWCztPVY+hgqMMaigFAF6tSXKnxca0LbS5eUGF1chkI2glFOUlbRGFx/5TpHN\nX8uCydaqX0tg4vF4Wnym1AWGCorLyTaal2EYV3YIJliVxeUkmTLIjLRxLwacWK+b6m700tCNHiKU\nVq7y70tdYKiguBi92pJ4PI5UKoVwOJz2AXUTRAiLoWdYoWTKIKMpysVDJkGzWmDIcweDwaIWGCoo\nLkTpylJ+CJXtUyoqKkzPijGr9QoAU1xcxep6UQtMtgrvUrDaWhtmC4yyjxl53Pz583H//ffbf3MF\nQD/JLoPUlhAxIR+uZDKJhoYGBAIBlJWVyadct226ZIYJz/OorKzMW0wync7cds/ZIMH9YDCISCSC\nUCgEj8cjpyhHo1G5qI7OgHGOQlxuRGD8fj9CoRAikYg8QptkYJI0f57nNT/DyhgOy7JYuXJlobdk\nO9RCcRF6Lq5oNCp33rVyNG+hGzXJ4gIgi54ZqE92xSYoatQpynrBX5K+3FpwUwylUIzE2ZQWjPq+\nBUEoSsuVCooLyNQ+hYxE1Wqf
2014-06-19 20:04:42 +00:00
"text": [
2014-06-20 19:53:01 +00:00
"<matplotlib.figure.Figure at 0x10905d0f0>"
2014-06-19 20:04:42 +00:00
]
}
],
2014-06-19 21:57:31 +00:00
"prompt_number": 11
2014-06-19 20:04:42 +00:00
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"point_x = np.array([[0],[0],[0]])\n",
"X_all = np.vstack((X_inside,X_outside))\n",
"\n",
"print('p(x) =', parzen_estimation(X_all, point_x, h=1))"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
"p(x) = 0.3\n"
]
}
],
2014-06-19 21:57:31 +00:00
"prompt_number": 12
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<br>\n",
"<br>"
]
2014-06-19 20:04:42 +00:00
},
{
"cell_type": "heading",
"level": 2,
"metadata": {},
"source": [
"Sample data and `timeit` benchmarks"
]
},
2014-06-19 21:57:31 +00:00
{
"cell_type": "markdown",
"metadata": {},
"source": [
"[[back to top](#Sections)]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In the section below, we will create a random dataset from a bivariate Gaussian distribution with a mean vector centered at the origin and a identity matrix as covariance matrix. "
]
},
2014-06-19 20:04:42 +00:00
{
"cell_type": "code",
"collapsed": false,
"input": [
"import numpy as np\n",
"\n",
"np.random.seed(123)\n",
"\n",
"# Generate random 2D-patterns\n",
"mu_vec = np.array([0,0])\n",
"cov_mat = np.array([[1,0],[0,1]])\n",
2014-06-20 19:53:01 +00:00
"x_2Dgauss = np.random.multivariate_normal(mu_vec, cov_mat, 10000)"
2014-06-19 20:04:42 +00:00
],
"language": "python",
"metadata": {},
"outputs": [],
2014-06-20 19:53:01 +00:00
"prompt_number": 13
2014-06-19 21:57:31 +00:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The expected probability of a point at the center of the distribution is ~ 0.15915 as we can see below. \n",
"And our goal is here to use the Parzen-window approach to predict this density based on the sample data set that we have created above. \n",
"\n",
"\n",
"In order to make a \"good\" prediction via the Parzen-window technique, it is - among other things - crucial to select an appropriate window with. Here, we will use multiple processes to predict the density at the center of the bivariate Gaussian distribution using different window widths."
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"from scipy.stats import multivariate_normal\n",
"var = multivariate_normal(mean=[0,0], cov=[[1,0],[0,1]])\n",
"print('actual probability density:', var.pdf([0,0]))"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
"actual probability density: 0.159154943092\n"
]
}
],
2014-06-20 19:53:01 +00:00
"prompt_number": 14
2014-06-19 21:57:31 +00:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<br>\n",
"<br>"
]
},
{
"cell_type": "heading",
"level": 2,
"metadata": {},
"source": [
"Benchmarking functions"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"[[back to top](#Sections)]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
2014-06-20 19:53:01 +00:00
"Below, we will set up benchmarking functions for our serial and multiprocessing approach that we can pass to our `timeit` benchmark function. \n",
"We will be using the `Pool.apply_async` function to take advantage of firing up processes simultaneously: Here, we don't care about the order in which the results for the different window widths are computed, we just need to associate each result with the input window width. \n",
"Thus we add a little tweak to our Parzen-density-estimation function by returning a tuple of 2 values: window width and the estimated density, which will allow us to to sort our list of results later."
2014-06-19 21:57:31 +00:00
]
2014-06-19 20:04:42 +00:00
},
2014-06-20 19:53:01 +00:00
{
"cell_type": "code",
"collapsed": false,
"input": [
"def parzen_estimation(x_samples, point_x, h):\n",
" k_n = 0\n",
" for row in x_samples:\n",
" x_i = (point_x - row[:,np.newaxis]) / (h)\n",
" for row in x_i:\n",
" if np.abs(row) > (1/2):\n",
" break\n",
" else: # \"completion-else\"*\n",
" k_n += 1\n",
" return (h, (k_n / len(x_samples)) / (h**point_x.shape[1]))"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 15
},
2014-06-19 20:04:42 +00:00
{
"cell_type": "code",
"collapsed": false,
"input": [
"def serial(samples, x, widths):\n",
" return [parzen_estimation(samples, x, w) for w in widths]\n",
"\n",
"def multiprocess(processes, samples, x, widths):\n",
2014-06-19 21:57:31 +00:00
" pool = mp.Pool(processes=processes)\n",
2014-06-20 19:53:01 +00:00
" results = [pool.apply_async(parzen_estimation, args=(samples, x, w)) for w in widths]\n",
" results = [p.get() for p in results]\n",
" results.sort() # to sort the results by input window width\n",
" return results"
2014-06-19 20:04:42 +00:00
],
"language": "python",
"metadata": {},
"outputs": [],
2014-06-20 19:53:01 +00:00
"prompt_number": 16
2014-06-19 21:57:31 +00:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Just to get an idea what the results would look like (i.e., the predicted densities for different window widths):"
]
2014-06-19 20:04:42 +00:00
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"widths = np.arange(0.1, 1.3, 0.1)\n",
"point_x = np.array([[0],[0]])\n",
"results = []\n",
"\n",
2014-06-19 21:57:31 +00:00
"results = multiprocess(4, x_2Dgauss, point_x, widths)\n",
2014-06-20 19:53:01 +00:00
"\n",
"for r in results:\n",
" print('h = %s, p(x) = %s' %(r[0], r[1]))"
2014-06-19 21:57:31 +00:00
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
2014-06-20 19:53:01 +00:00
"h = 0.1, p(x) = 0.016\n",
"h = 0.2, p(x) = 0.0305\n",
"h = 0.3, p(x) = 0.045\n",
"h = 0.4, p(x) = 0.06175\n",
"h = 0.5, p(x) = 0.078\n",
"h = 0.6, p(x) = 0.0911666666667\n",
"h = 0.7, p(x) = 0.106\n",
"h = 0.8, p(x) = 0.117375\n",
"h = 0.9, p(x) = 0.132666666667\n",
"h = 1.0, p(x) = 0.1445\n",
"h = 1.1, p(x) = 0.157090909091\n",
"h = 1.2, p(x) = 0.1685\n"
2014-06-19 21:57:31 +00:00
]
}
],
2014-06-20 19:53:01 +00:00
"prompt_number": 17
2014-06-19 21:57:31 +00:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
2014-06-20 15:09:14 +00:00
"Based on the results, we can say that the best window-width would be h=1.1, since the estimated result is close to the actual result ~0.15915. \n",
"Thus, for the benchmark, let us create 100 evenly spaced window width in the range of 1.0 to 1.2."
2014-06-19 21:57:31 +00:00
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<br>\n",
"<br>"
]
},
2014-06-20 15:09:14 +00:00
{
"cell_type": "code",
"collapsed": false,
"input": [
2014-06-20 19:53:01 +00:00
"widths = np.linspace(1.0, 1.2, 100)"
2014-06-20 15:09:14 +00:00
],
"language": "python",
"metadata": {},
"outputs": [],
2014-06-20 19:53:01 +00:00
"prompt_number": 18
2014-06-20 15:09:14 +00:00
},
2014-06-19 21:57:31 +00:00
{
"cell_type": "code",
"collapsed": false,
"input": [
"import timeit\n",
"\n",
"mu_vec = np.array([0,0])\n",
"cov_mat = np.array([[1,0],[0,1]])\n",
2014-06-20 19:53:01 +00:00
"n = 10000\n",
2014-06-19 21:57:31 +00:00
"\n",
"x_2Dgauss = np.random.multivariate_normal(mu_vec, cov_mat, n)\n",
"\n",
"benchmarks = []\n",
"\n",
"benchmarks.append(timeit.Timer('serial(x_2Dgauss, point_x, widths)', \n",
2014-06-19 20:04:42 +00:00
" 'from __main__ import serial, x_2Dgauss, point_x, widths').timeit(number=1))\n",
"\n",
2014-06-19 21:57:31 +00:00
"benchmarks.append(timeit.Timer('multiprocess(2, x_2Dgauss, point_x, widths)', \n",
2014-06-19 20:04:42 +00:00
" 'from __main__ import multiprocess, x_2Dgauss, point_x, widths').timeit(number=1))\n",
"\n",
2014-06-19 21:57:31 +00:00
"benchmarks.append(timeit.Timer('multiprocess(3, x_2Dgauss, point_x, widths)', \n",
2014-06-19 20:04:42 +00:00
" 'from __main__ import multiprocess, x_2Dgauss, point_x, widths').timeit(number=1))\n",
"\n",
2014-06-19 21:57:31 +00:00
"benchmarks.append(timeit.Timer('multiprocess(4, x_2Dgauss, point_x, widths)', \n",
2014-06-19 20:04:42 +00:00
" 'from __main__ import multiprocess, x_2Dgauss, point_x, widths').timeit(number=1))\n",
"\n",
2014-06-19 21:57:31 +00:00
"benchmarks.append(timeit.Timer('multiprocess(6, x_2Dgauss, point_x, widths)', \n",
2014-06-19 20:04:42 +00:00
" 'from __main__ import multiprocess, x_2Dgauss, point_x, widths').timeit(number=1))"
],
"language": "python",
"metadata": {},
2014-06-19 21:57:31 +00:00
"outputs": [],
2014-06-20 19:53:01 +00:00
"prompt_number": 19
2014-06-19 21:57:31 +00:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<br>\n",
"<br>"
]
},
{
"cell_type": "heading",
"level": 2,
"metadata": {},
"source": [
"Preparing the plotting of the results"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"[[back to top](#Sections)]"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"import platform\n",
"\n",
"def print_sysinfo():\n",
" \n",
" print('\\nPython version :', platform.python_version())\n",
" print('compiler :', platform.python_compiler())\n",
" \n",
" print('\\nsystem :', platform.system())\n",
" print('release :', platform.release())\n",
" print('machine :', platform.machine())\n",
" print('processor :', platform.processor())\n",
" print('CPU count :', mp.cpu_count())\n",
" print('interpreter:', platform.architecture()[0])\n",
" print('\\n\\n')"
],
"language": "python",
"metadata": {},
"outputs": [],
2014-06-20 19:53:01 +00:00
"prompt_number": 20
2014-06-19 21:57:31 +00:00
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"from matplotlib import pyplot as plt\n",
"import numpy as np\n",
"\n",
"def plot_results():\n",
" bar_labels = ['serial', '2', '3', '4', '6']\n",
"\n",
" fig = plt.figure(figsize=(10,8))\n",
"\n",
" # plot bars\n",
" y_pos = np.arange(len(benchmarks))\n",
" plt.yticks(y_pos, bar_labels, fontsize=16)\n",
2014-06-20 15:09:14 +00:00
" bars = plt.barh(y_pos, benchmarks,\n",
2014-06-19 21:57:31 +00:00
" align='center', alpha=0.4, color='g')\n",
"\n",
" # annotation and labels\n",
2014-06-20 15:09:14 +00:00
" \n",
" for ba,be in zip(bars, benchmarks):\n",
2014-06-20 19:53:01 +00:00
" plt.text(ba.get_width() + 2, ba.get_y() + ba.get_height()/2,\n",
2014-06-20 15:09:14 +00:00
" '{0:.2%}'.format(benchmarks[0]/be), \n",
" ha='center', va='bottom', fontsize=12)\n",
" \n",
2014-06-19 21:57:31 +00:00
" plt.xlabel('time in seconds for n=%s' %n, fontsize=14)\n",
" plt.ylabel('number of processes', fontsize=14)\n",
" t = plt.title('Serial vs. Multiprocessing via Parzen-window estimation', fontsize=18)\n",
" plt.ylim([-1,len(benchmarks)+0.5])\n",
2014-06-20 19:53:01 +00:00
" plt.xlim([0,max(benchmarks)*1.1])\n",
2014-06-20 15:09:14 +00:00
" plt.vlines(benchmarks[0], -1, len(benchmarks)+0.5, linestyles='dashed')\n",
2014-06-19 21:57:31 +00:00
" plt.grid()\n",
"\n",
" plt.show()"
],
"language": "python",
"metadata": {},
"outputs": [],
2014-06-20 19:53:01 +00:00
"prompt_number": 25
2014-06-19 21:57:31 +00:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<br>\n",
"<br>"
]
},
{
"cell_type": "heading",
"level": 1,
"metadata": {},
"source": [
"Results"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"[[back to top](#Sections)]"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"plot_results()\n",
"print_sysinfo()"
],
"language": "python",
"metadata": {},
2014-06-19 20:04:42 +00:00
"outputs": [
{
2014-06-19 21:57:31 +00:00
"metadata": {},
"output_type": "display_data",
2014-06-20 19:53:01 +00:00
"png": "iVBORw0KGgoAAAANSUhEUgAAAowAAAIACAYAAAAIQT11AAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJzs3Xl8TPf6B/DPmZBVElmERGWzFQlFaFGyqL3V2kKqIfYt\nqm7Rlt4mVAVxKbXUls3FrSD2NRJL0LpibWuXxBZLbElIJJHz+8NvzjVmJjPImJP4vF8vr3bOnDnn\nmfPM8uScZ75fQRRFEUREREREWiiMHQARERERyRsLRiIiIiIqEQtGIiIiIioRC0YiIiIiKhELRiIi\nIiIqEQtGIiIiIioRC0YCAOzduxcKhQKxsbGvvA2FQoEBAwaUYlRln5+fHzw8PPRePyQkBAoF35a6\npKenQ6FQYPLkycYORW/u7u7w9/c3dhikhaE+v8ria7U0lYXnHxMTA4VCgX379hk7FFnjN5MMXb58\nGUOHDsW7774LKysr2Nvbo379+ggJCcHevXsNtl9BECAIwmtvQ+6URZlCoUBqaqrGdebMmSOt8zpF\nNKB+TGJiYjB37lyt65aFYygXZelYGSq37u7u0mtVoVDAzMwMHh4eGDJkCK5du1bq+yvPDPl6Kkuv\n1ZeVnp6O8PBwnDx5Uus6xn7+e/fuxeTJk/Hw4UO1+5TvTWPHKHcVjB0AqTp69Ch8fX1hZmaGfv36\noUGDBsjLy8P58+exa9cu2NjYwM/Pr9T36+vri7y8PFSo8Pa8JMzNzREdHY2mTZuq3RcdHQ1zc3Pk\n5+eX+odITEwMMjIyMGbMGLX7li5disWLF5fq/sojd3d35Ofnw8TExNih6O38+fMG+0KqUaMGIiIi\nAAA5OTlITk5GVFQUtm3bhlOnTsHBwcEg+y1PytrrSU7S09MxZcoUeHp6olGjRir3yeW9unfvXkyZ\nMgUDBgyAra2tyn3BwcEICgpCxYoVjRRd2fD2VAdlxOTJk5Gfn4/ff/8d3t7eavffunWrVPeXk5MD\na2trCIIAU1PTUt223HXr1g2rV6/G7NmzVZ77f//7X/z555/4/PPPsWrVKoPsW1vhYKiCPTc3F5Uq\nVTLIto2lrL1eDfllZGtri88//1y6PWzYMDg5OWH+/PmIjo7GuHHjXnsfys+K8qqsvZ7kSNvEcXI6\ntppiVCgUsopRrnhJWmYuXLgABwcHjcUiAFStWlVtWWJiItq3bw87OztYWFigUaNGGs9SKXuojh8/\njg4dOqBy5crSX4OaehhFUcRPP/2ENm3awNnZGWZmZnBzc8PIkSNx7969V3p+Z86cgUKhwNdff63x\n/qCgIJiZmeHu3bsAgKtXr2LgwIFwc3ODubk5qlatilatWiEuLu6V9v+8AQMG4P79+9iwYYPK8ujo\naDg5OeHjjz9We4yy12X//v1q9+nTr+ju7o79+/dLfT3Kf8rtaephVC7LyspCv3794OjoiEqVKuGj\njz7C8ePHVdZ9vl/ot99+Q9OmTWFpaYnRo0dL6yxbtgxNmjSBpaUlKleujA4dOuDgwYMa401OTkaX\nLl3g4OAACwsL1KxZE4MHD5byo/Tbb7/hww8/hI2NDaysrPDBBx9g3bp1atvbunUrfH19UaVKFVha\nWsLNzQ09evTAhQsXpHX0ybmmvqjnl23ZsgXNmjWDhYUFXFxcMGHCBDx9+lQtnnXr1qFRo0awsLCA\nm5sbpkyZgsTERL1aEb755hsoFAqcPn1a7b6HDx/CwsIC3bp1k5Zp6mHctWsXevfuDU9PT1haWsLO\nzg4dOnTQ+Pp6We3btwcAXLp06aX3pXwtp6WloWfPnrC3t5fOyrx4Cfz5fy8+v6NHj6Jbt26oUqUK\nzM3N8e6772LatGlquVDuLzMzE0FBQbC3t4eVlRU6duyo8tooyYABA2BhYYEnT55Iyw4fPgyFQgEH\nBweVQmH79u1QKBSIj4+XlmnqYVQuO3z4MHx9fVGpUiU4OjpiyJAhePTokVoMKSkpaNWqFSwtLVGt\nWjWMHj0aubm5GuN99OgRvvvuO9SsWRPm5uZwdnZG//79ceXKFWmdJ0+ewMLCAiEhISqPHTZsGBQK\nBb766iuV5b1794atrS2Ki4t1Hq8LFy4gODhY+mz38PDAhAkT8PjxY5X1dL0fY2JiEBAQAOBZDl58\nLeh6r65duxbvvfceLC0tUatWLSxbtgwAkJGRgZ49e8LBwQE2NjYIDg5WO5Znz57FyJEj0aBBA+mz\nx8fHB8uXL1dZLyQkBFOmTAEAeHh4SDEql2n7XM/KysKoUaNQo0YNmJmZwdXVFaGhoWrff8rHJycn\nY9asWVJO69atWyrfVXLBM4wyU6tWLWzbtg0JCQkqXzbaLFmyBMOHD0fLli3x/fffw8rKCrt27cKI\nESNw6dIlzJw5U1pXEARcuXIFbdu2RWBgIHr16qX2Bnz+zNeTJ08wa9Ys9OzZE926dYOVlRWOHDmC\n5cuXIyUlBampqS991qRevXpo1qwZVq1ahcjISJXiKDs7Gxs3bkTnzp3h4OCAoqIitGvXDjdu3MCo\nUaNQp04dPHz4ECdPnkRKSgr69ev3Uvt+8Xk2btwY7733HqKiohAYGAjg2WWp1atXY9CgQa90RkjX\nJce5c+fiu+++Q1ZWFn7++Wdpeb169XRuo2PHjnBwcMDkyZORmZmJ+fPnw9fXF4cPH0aDBg1U1t2w\nYQOuXLmCkSNHYuTIkbCxsQHwrMiJjIzE+++/j4iICGRnZ2PJkiXw9/fHxo0b0alTJ2kbixcvxogR\nI1CjRg2MGjUKbm5uyMjIwJYtW3D9+nXpMuf333+PadOmoVOnTpg6dSoUCgXWr1+PXr16Yf78+Rg5\nciQAYN++fejatSsaNmyIiRMnonLlyrh+/Tr27NmDS5cuoXbt2i+dc03Hatu2bVi4cCFGjBiBwYMH\nY8OGDZg1axbs7Ozw3XffSev99ttvCAoKQu3atREeHg4TExPExsZi8+bNeuUyJCQEkZGRiIuLQ2Rk\npMp9a9aswZMnT1S+6DX1SMXGxuLBgwcICQnBO++8g2vXrmHZsmVo27YtkpOT8eGHH5YYQ0mUhZaj\no+NL70sQBOTm5sLX1xcffvghIiIicPv2bQDPXsMvFku///475s+fj2rVqknLtm7diu7du6NOnToY\nN24c7O3tcejQIfzwww84ceIE1qxZo7K/R48eoU2bNmjRogUiIiJw+fJlzJ07F59++in+/PNPnT8G\na9u2LWJjY3Hw4EGpgNmzZw8UCgUePHiA48ePo0mTJgCApKQkjQWuppyfOHECn3zyCQYOHIgvvvgC\nycnJWL58ORQKhcof5n/88Qc++ugj2Nra4ttvv4WtrS3+85//aPxjrLCwEB06dMChQ4fQq1cvjB8/\nHufPn8eiRYuwa9cuHD16FNWrV4eZmRlatWqF5ORklccrn1dSUpK0TBRF7N27F23atNF5rFJTUxEQ\nEAB7e3uMGDEC1atXx4kTJzBv3jwcPHgQ+/btQ4UKFfR6P/r6+mLixImYNm0ahg0bhtatWwNQP7mh\n6dhu2bIFv/76K0aNGgV7e3ssW7YMQ4cOhYmJCcLCwtCuXTtERETgyJEjiIqKgrm5OZYuXSo9ft++\nfThw4AC6du0KDw8PPHr0CGvWrMGQIUNw584dfPvttwCA4cOHIycnBwkJCfj555+l90TDhg21HqOH\nDx+iZcuWuHTpEgYNGoQmTZrg2LFjWLRoEZKSknDkyBG1qzYTJ05Efn4+RowYAVNTUyxatAghISGo\nVasWWrZsWWJOygSRZOXw4cOiqampKAiCWLt2bXHAgAHiokWLxDNnzqite+PGDdHMzEzs27ev2n1j\nxowRTUxMxMuXL0vL3NzcREEQxOXLl6utn5ycLAqCIMbGxqosz8/PV1t3+fLloiAI4po1a1SWC4Ig\nDhgwQOdzXLBggSgIgrht2zaV5cuWLRMFQRATEhJEURTFkydPioIgiJGRkTq3+TL69+8vCoIgZmVl\nib/88otoYmIiXrt2TRRFUVy5
2014-06-19 21:57:31 +00:00
"text": [
2014-06-20 19:53:01 +00:00
"<matplotlib.figure.Figure at 0x10f1dd160>"
2014-06-19 21:57:31 +00:00
]
},
{
"output_type": "stream",
"stream": "stdout",
"text": [
"\n",
"Python version : 3.4.1\n",
"compiler : GCC 4.2.1 (Apple Inc. build 5577)\n",
"\n",
"system : Darwin\n",
"release : 13.2.0\n",
"machine : x86_64\n",
"processor : i386\n",
"CPU count : 4\n",
"interpreter: 64bit\n",
"\n",
"\n",
"\n"
2014-06-19 20:04:42 +00:00
]
}
],
2014-06-20 19:53:01 +00:00
"prompt_number": 26
2014-06-19 20:04:42 +00:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
2014-06-19 21:57:31 +00:00
"<br>\n",
"<br>"
2014-06-19 20:04:42 +00:00
]
},
{
"cell_type": "heading",
2014-06-20 19:53:01 +00:00
"level": 1,
2014-06-19 20:04:42 +00:00
"metadata": {},
"source": [
2014-06-19 21:57:31 +00:00
"Conclusion"
2014-06-19 20:04:42 +00:00
]
},
{
2014-06-19 21:57:31 +00:00
"cell_type": "markdown",
2014-06-19 20:04:42 +00:00
"metadata": {},
"source": [
2014-06-19 21:57:31 +00:00
"[[back to top](#Sections)]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
2014-06-21 03:12:26 +00:00
"We can see that we could speed up the density estimations for our Parzen-window function if we submitted them in parallel. However, on my particular machine, the submission of 6 parallel 6 processes doesn't lead to a further performance improvement, which makes sense for a 4-core CPU. \n",
"We also notice that there was a significant performance increase when we were using 3 instead of only 2 processes in parallel. However, the performance increase was less significant when we moved up to 4 parallel processes, respectively. \n",
"This can be attributed to the fact that in this case, the CPU consists of only 4 cores, and system processes, such as the operating system, are also running in the background. Thus, the fourth core simply does not have enough capacity left to further increase the performance of the fourth process to a large extend. And we also have to keep in mind that every additional process comes with an additional overhead for inter-process communication. \n",
"\n",
"Also, an improvement due to parallel processing only makes sense if our tasks are \"CPU-bound\" where the majority of the task is spent in the CPU in contrast to I/O bound tasks, i.e., tasks that are processing data from a disk. "
2014-06-19 20:04:42 +00:00
]
2014-06-21 03:12:26 +00:00
},
{
"cell_type": "code",
"collapsed": false,
"input": [],
"language": "python",
"metadata": {},
"outputs": []
2014-06-19 20:04:42 +00:00
}
],
"metadata": {}
}
]
}